Building an AI Background Remover That Runs Entirely in Your Browser
September 15, 2025 by Shahriar Ahmed Shovon
Note: For those interested in the broader implications of running AI models in browsers, I recommend exploring the transformers.js documentation and the Hugging Face model hub. This article focuses on the practical engineering challenges of implementing client-side machine learning.
Web developers often treat AI as a black box that requires server infrastructure, GPU clusters, and complex deployment pipelines. In reality, modern browsers have evolved into capable platforms for running sophisticated machine learning models locally. This article examines how I built a privacy-first background removal tool that runs entirely in the browser, leveraging transformers.js and the RMBG-1.4 segmentation model.
The goal is a developer-focused explanation that demystifies client-side AI implementation, covering everything from model integration and Web Worker orchestration to memory optimization and image processing pipelines. We’ll explore the technical decisions that make browser-based AI both feasible and performant.
The Architecture Decision
Every AI application begins with a fundamental choice: where does the computation happen? Traditional approaches route user data to cloud services for processing—a pattern that works but introduces privacy concerns, latency, and ongoing infrastructure costs.
When I decided to build a background remover, the constraint was clear: zero uploads, complete privacy. This requirement led to an architecture where the browser itself becomes the AI runtime environment.
The implementation leverages several key technologies:
transformers.js: A JavaScript library that brings Hugging Face models to browsers
RMBG-1.4: A state-of-the-art image segmentation model optimized for background removal
Web Workers: Background threads that handle intensive computations without blocking the UI
Canvas API: For low-level image manipulation and format conversion
Model Integration: The First Challenge
Getting transformers.js to work with the RMBG-1.4 model presented immediate complexities. Unlike server environments where you control the runtime, browsers impose strict limitations on memory, processing power, and file system access.
The model configuration required careful tuning:
| |
The preprocessing pipeline had to match exactly what the model expected during training. Incorrect normalization values or resizing algorithms would result in poor segmentation quality. This configuration took significant experimentation to get right.
The Image Processing Pipeline
The second major challenge involved converting the model’s output into something users could actually download. AI segmentation models output masks—essentially grayscale images that indicate what should be kept versus removed. Users need transparent PNGs.
The conversion process involves multiple steps:
Image Loading: Convert the uploaded file into a format the model can process
Model Inference: Generate the segmentation mask
Mask Processing: Resize the mask back to the original image dimensions
Alpha Channel Application: Apply the mask to create transparency
Format Conversion: Generate a downloadable PNG with proper transparency
Each step required careful handling of different image formats, color spaces, and pixel layouts. The browser’s Canvas API became crucial for manipulating raw pixel data:
| |
Memory Optimization Strategy
Running a 44MB model in a browser environment demanded aggressive memory management. Browsers have much stricter memory limits than server environments, and users often have multiple tabs open competing for resources.
The optimization strategy involved several techniques:
Background Threading: All heavy computation moves to Web Workers, preventing main thread blocking and allowing the browser to manage memory more efficiently across threads.
Lazy Loading: The model only loads when first needed, not during initial page load. Subsequent uses leverage the cached model.
Resource Cleanup: Explicit disposal of intermediate data structures and Canvas contexts after processing completes.
Tile-Based Processing: For very large images, the system could theoretically break processing into smaller tiles to manage peak memory usage, though the current implementation processes images holistically.
The Web Worker architecture proved essential for this strategy:
| |
Performance Characteristics
The final implementation processes typical images (1-5MB) in under 5 seconds on modern hardware. Performance breaks down roughly as:
- Model download (first time only): Variable based on connection
- Image preprocessing: ~500ms
- Model inference: ~2-3 seconds
- Post-processing and format conversion: ~500ms
The first-time experience requires downloading the 44MB model, which happens in the background with progress indicators. Subsequent uses are nearly instant since everything is cached locally.
Implications for Web Development
This project demonstrates that sophisticated AI applications don’t require complex backend infrastructure. The privacy-first, offline-capable approach offers several advantages:
User Privacy: No data leaves the device, eliminating privacy concerns and compliance complexity.
Latency: No network round trips after initial model download.
Scalability: Zero server costs regardless of usage volume.
Availability: Works offline after initial load, making it resilient to network issues.
The trade-offs involve higher memory usage, longer initial load times, and dependency on client-side processing power. But as browsers and devices become more capable, these constraints become less limiting.
The Future of Client-Side AI
Browser-based machine learning represents a fundamental shift in how we think about AI deployment. Instead of centralizing computation in data centers, we’re distributing it to edge devices where the data already exists.
This approach aligns with broader trends toward privacy-preserving computation, edge AI, and reducing cloud dependency. Libraries like transformers.js make this pattern accessible to web developers without requiring deep ML expertise.
The background remover serves as a proof of concept for what’s possible today. As WebAssembly improves, WebGL compute shaders become more accessible, and models become more efficient, we’ll likely see more sophisticated AI applications running entirely in browsers.
The web platform continues to evolve into a powerful runtime environment—one that increasingly doesn’t need the cloud to deliver intelligent, responsive user experiences.
Explore the Implementation
The complete source code, live demonstration, and detailed technical documentation are available for developers interested in building similar client-side AI applications:
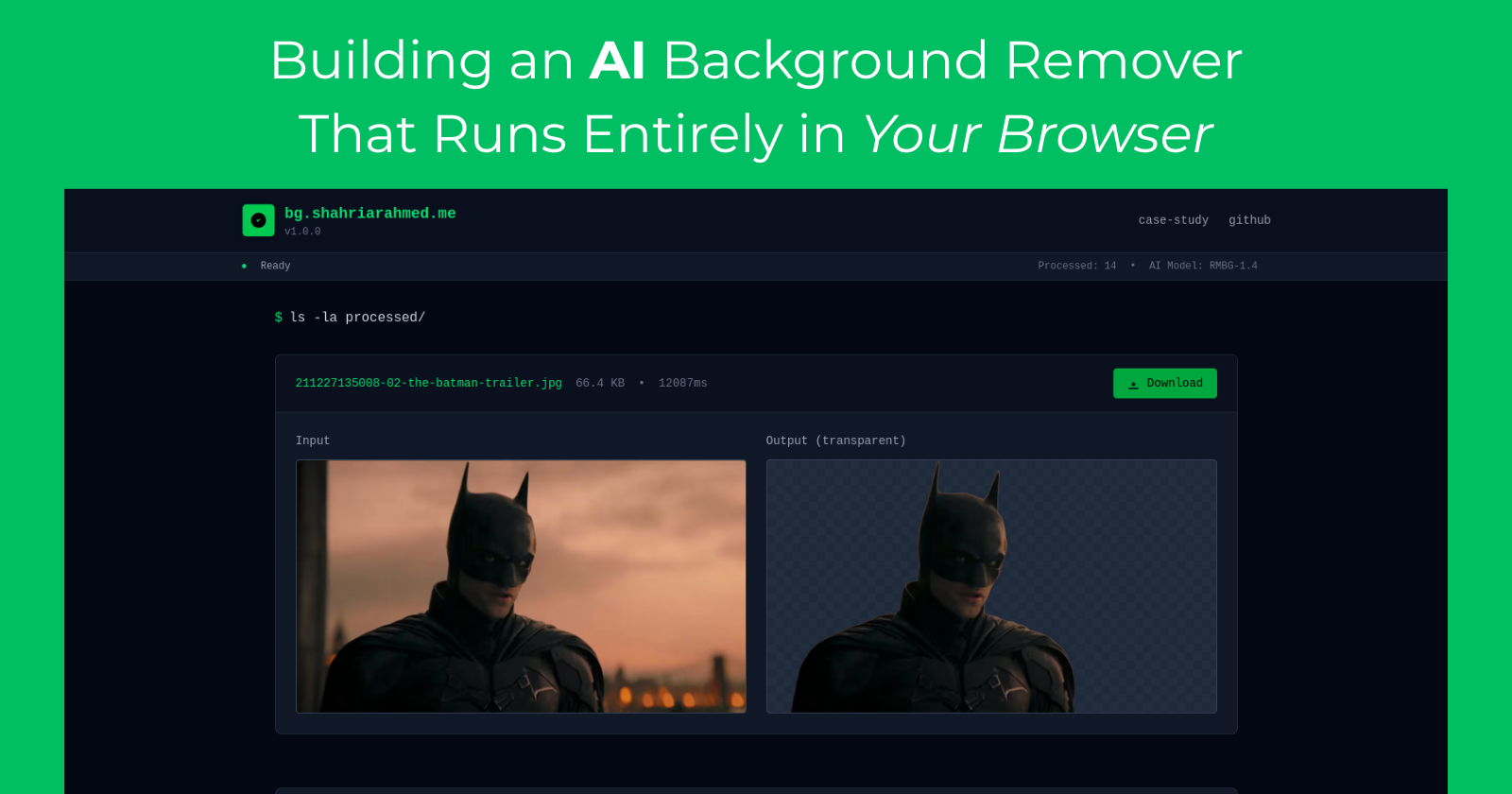
Live Demo: Experience the background remover in action at bg.shahriarahmed.me. Upload any image and see real-time processing with full privacy guarantees.
GitHub Repository: The complete implementation is open source at github.com/shahriarAS/bg-remover, including the Web Worker architecture, model integration patterns, and image processing pipeline. The codebase demonstrates production-ready patterns for browser-based ML applications.
Case Study: A comprehensive technical case study with performance metrics, architecture diagrams, and implementation details is available at shahriarahmed.me/case-study/bg-remover.
These resources provide the foundation for developers to implement their own client-side AI applications, whether for image processing, natural language tasks, or other machine learning workloads that benefit from local execution.
This implementation showcases the convergence of web technologies, machine learning, and privacy-focused design. The complete architecture runs in any modern browser, proving that the future of AI might be more distributed than centralized.
Discover More
About
This is my personal blog, where I write about various topics related to software development, technology, and my own experiences. I enjoy exploring new technologies, frameworks, and programming languages, and sharing what I learn with others.

